

はじめに
自分への戒めも込めて、技術ブログの書き方について検討しました。
私自身も、良い技術記事の書き方は探求中です。
状況や要件によって求められるものは違いますので、
ぜひ、皆様の最強の技術記事の書き方を考えるきっかけになればと思います。
技術ブログの目的、役割
- IT技術に関する悩みを解決する
- ユーザー目線でのドキュメント整備
- 技術をアウトプットし、自分の知識を深める
閲覧者のニーズ
- 今使う、具体的な情報を知りたい
- 今後、どう行動するべきか知りたい
- 読み物として楽しみたい
ざっとまとめてみました。
実際にはもっと沢山あるかもしれませんね。
注意
!注意 この記事のコード例はLLMの出力をベースにしているため
動作することを保証しません。
python,C#にて記載しています。雰囲気が分かれば大丈夫です。
コマンド例は、linuxコマンドを想定しています。コピペのしやすさを考慮しよう
以下にコピペを難しくしてしまい、利便性が低下する例と要因を示します。
過剰なコメントが含まれている
# ここでFastAPIをインポートします
# from import句にて、FastAPI()関数をプログラム内に読み込みます
from fastapi import FastAPI
# FastAPIアプリケーションの初期化
# FastAPi関数を実行しapp変数に格納します
app = FastAPI()
# ルートエンドポイントの作成
# @はPython言語でのデコレータを表します
# /とは一般的にルートを表し、ルートとは根と表すこともあります。
# Helloとは英語にて……
@app.get("/")
def read_root():
return {"message": "Hello, FastAPI"}全くの初心者には理解を手助けすることができるかもしれません。
しかし、ただコードをコピペしたい人にコメントは不要です。
- 全部コピーして、コメントを削る
- コメント以外を随時コピーしていく
思いの外、負荷が高いです。
横コメント
using (HttpClient httpClient = new HttpClient()) // HttpClientの初期化
{
string apiUrl = "https://example.com"; // 適切なURLに変更してください。
HttpResponseMessage response = await httpClient.GetAsync(apiUrl);
} コピペするマウス操作の難易度が上がります。
コメントを削りすぎて、コードまで削るという可能性と、心理的不安が大きいです。
$ 記号の正しい利用
コマンドを表す $ 記号ですが、コピペするときに支障がでることがあります。
説明するコマンドは$があると理解しやすいです。
短いコマンドや典型的なコマンドである場合、コマンドを実行するんだな~と理解できます。
$ python -m venv venv一方で長く、コピペすることが前提のコマンドの場合
$ openstack image create "cirros-threepart-ramdisk" \
--disk-format ari --container-format ari --public \
--file ~/images/cirros-0.3.5-x86_64-initramfsとりあえずコピーしよう。→ $ 記号も付いてきちゃった…
対応としては、
$記号を使わない、あるいは、$部分のコピーができない仕組みを作る。
また、コピーボタンを設置することで対応できそうです。
すごい複雑にクラス化されている
class Hello:
def __init__(self, message):
self.message = message
def get_message(self):
return self.message
class Person(Hello):
def __init__(self, name):
super().__init__("こんにちは")
self.name = name
def greet(self):
return f"{self.get_message()} {self.name} さん"
class Greeting:
def generate_greeting(self, name):
person = Person(name)
return person.greet()
# 使用例
if __name__ == "__main__":
greeting = Greeting()
name_to_greet = "太郎"
result = greeting.generate_greeting(name_to_greet)
print(result)$ python3 class_nagai.py
> こんにちは 太郎 さんふざけすぎましたかね?
短い機能なら、保守性や安全性よりも、コピペを重視して良いと思います。
JavaやC++などの言語の場合は、しっかり記載することが必要な場合がありますが、
How Toの情報と、運用は別だと考えます。
また、クラス化は自分のスタイルでやりたいよ!という場合も多いです。
再利用できるものはクラス化
一方で、再利用できるものはクラス化した上で公開して良いと思います。
以下はCNNという画像認識モデルをkerasにて実装したものです。(イメージ)
class CNN:
def __init__(self, input_shape=(28, 28, 1), num_classes=10):
self.model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=input_shape),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax')
])
def train(self, X_train, y_train, epochs=10, batch_size=128):
self.model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
self.model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size)
def
predict(self, X_test):
return self.model.predict(X_test)決まりきったものを実装する際は、クラスとしてまとめてあると便利です。
あまりにも長いクラスの場合は、GitHubにて公開したほうが良いですね。
再現性がある
環境のバージョン情報が記載されていると、環境起因の不具合であるか?の切り分けできます。
言語バージョン
$ python -V
> Python 3.10.12ライブラリリスト
$ pip list
PyYAML 5.4.1
requests 2.25.1ライブラリのリストを出力できるなら、添付する
$ pip freeze > requirements.txtrequirements.txt
blinker==1.7.0
click==8.1.7
Flask==3.0.0
itsdangerous==2.1.2
Jinja2==3.1.3
MarkupSafe==2.1.3
numpy==1.26.3
Werkzeug==3.0.1OSの種類、バージョン
Linuxカーネル
$ uname -r
> 5.10.102.1-microsoft-standard-WSL2Windowsバージョン
$ winverGUIで開きます。
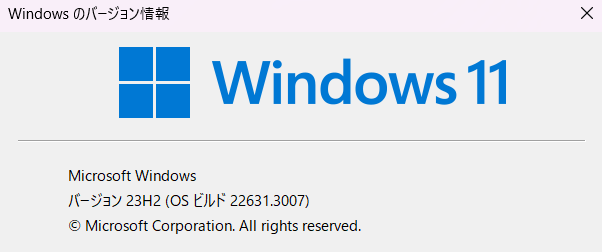
Linuxディストリビューション
cat /etc/*release
cat /etc/*version
$ cat /etc/*-release
> DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=22.04
DISTRIB_CODENAME=jammy
DISTRIB_DESCRIPTION="Ubuntu 22.04.3 LTS"
PRETTY_NAME="Ubuntu 22.04.3 LTS"
NAME="Ubuntu"
VERSION_ID="22.04"
VERSION="22.04.3 LTS (Jammy Jellyfish)"
VERSION_CODENAME=jammy
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=jammy沢山出てくるので、手動で抜き出すか、grepで絞り込む
ハードウェア
ハードウェアに起因する機能の場合は、機器の情報やファームウェア情報もあると、役に立つでしょう。
ハードウェア起因の場合は、デバックが難しいからです。
結果を教えて、どうなったら正常?
動いたけど、合ってるの?
説明は理解した。実行してみよう。
x = 3
y = 5
result = ((x ** y + z) * math.pi - (offset * 2) * ratio)
print(result)結果がprint された。56.25と出力された。
正常に計算できているのだろうか?
printした結果を残しておくとよい
result = ((x ** y + z) * math.pi - (offset * 2) * ratio)
print(result)
> 56.25print部分を抜き出してもいいかも
print(result)
> 56.25CLIは動いてる?
npm run devでサーバーを起動します。
$ npm run dev実行できましたね。では次に……
起動したっぽいが…?これで正常?
npm run devを実行すると、ターミナルは以下のような状態になります。
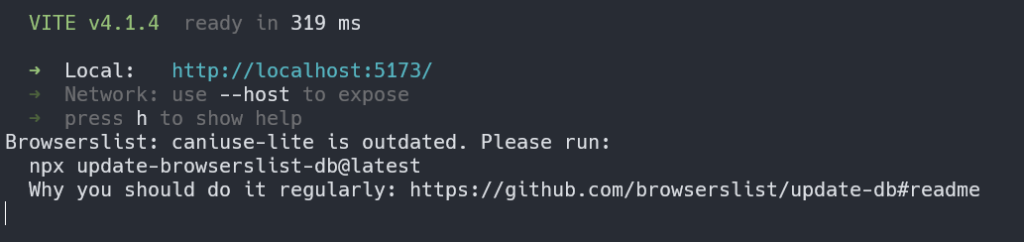
このように実行結果を示す、スクリーンショットを添付すると親切ですね。
特に入門記事や、環境構築を解説する記事では有効性が高いです。
口調
一般的な話ではありますが…
思います
XXX関数は、YYYというアルゴリズムを実装したものだと思います…?
確認できることはできる限り調べるようにしましょう。
ですます
である。です。で言い切る
公式ドキュメントによるとYYYです。と根拠を示す。
公式ドキュメントを探しましたが、YYYなのかは分かりませんでした。
とりあえず動きますが、ご注意ください。
学術論文ではないので厳密性を求めすぎても大変だと思います。
結果を確認するコマンド
バックグラウンドで動作するツール系
バックグラウンドで動作するツールなど、エラーが見えにくい場合は、
正常に動作しているか?を確認するコマンドも実行させると親切です。
Xの設定を変更します。
では次に進みます。
nginx.confのXXXという部分を書き換えます。
以下のコマンドで、コンフィグが正常か確認できます。
エラーが有るなら、エラーが表示され、なければコンフィグが表示されます。
$ nginx -T以下のコマンドでnginxが起動しているか確認します
sudo service nginx status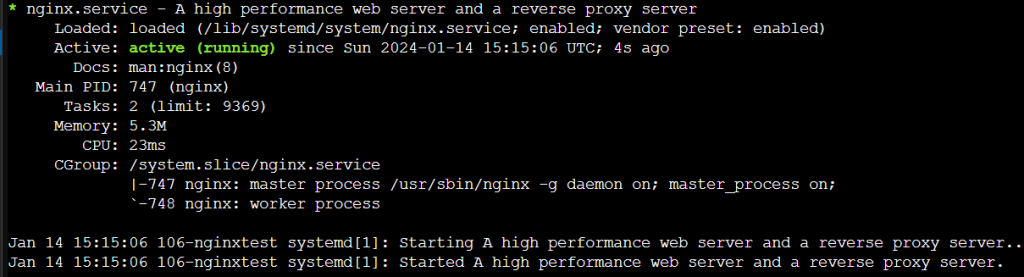
手動で打った変更を確認する
以下をconfig.jsonに追記します。
$ nano config.json
MAX_SIZE = 512M
POST_MAX_SIZE = 512M
OPTION1 = ON以下のコマンドで正しく設定が完了しているか確認します。
$ grep -E "^MAX_SIZE|^POST_MAX_SIZE|^OPTION1" config.json値が追記されている場合、結果は次の画像のようになります。

grepコマンドをこだわる事も可能です。
しかし、長いコマンドをWEB上の記事から実行することは、セキュリティ上の不安があります。
重要な設定や、あまり構造化されていないファイルの場合は自動でチェックすると安心でしょう。
例 : grub等のブートオプションなど
余計な情報と必要な情報
関数の使い方が知りたい人向けの情報
- 使い方
- 機能
- 注意点
が知れれば満足なことが多いと思います。
因数や返り値を記載してもよいが、公式ドキュメントを見るほうが正確で、情報の追従性があります。
XXXはどのように運用するべきか?的な記事
読み物としても読まれる事が多いでしょう。
唯一無二の体験であるため、WEB上に複数の記事や意見があっても良いと思います。
物語のような構成でも理解しやすいです。
技術記事の立ち位置とデザイン
概ね以下のような関係にあるかな?と思います。
メモ ←→ 情報 ←→ 読み物
エンジニア向けならサイトのデザインには、そこまで凝らなくてもよいです。
また、Markdownに近いほうが理解しやすい傾向にあると思います。
エラーはどの程度想定するべきか
典型的なエラー例が記載されていると親切ではあります。
しかし、全てのエラーを網羅することは不可能に近いです。
一方で、自分がハマったエラーを記事に書くと良いです。
また同じ過ちを犯す可能性が高いからです。
特に思い込みが原因の場合は、記事にしなくてもメモしておくとよいです。
例えば…
画像処理のopencvライブラリのpythonバインディングをインストールしたい時に…
// 目的のライブラリではない
$ pip install opencv
// 正しい
$ pip install opencv-python記事作成コストと有用性
これまで色々書きましたが、全部遵守するのは大変です。
完璧な記事を少数書くか、そこそこな記事を沢山書くか?
質か量かの問題です。
ニッチなライブラリ等の情報は存在するだけで、価値が高い場合があります。
検索しても英語記事しかヒットしない中、日本語で書いてる記事がある!
なんて経験したことはないですか?
一方で、ニッチなライブラリを利用したい人は既に基本的な概念は理解していると思います。
メモ程度の記事でも、刺さる人に刺さる情報になることがあります。
SEOの観点から見ると、ユーザビリティに配慮されていた、有用な記事が、検索エンジンには好まれると思われます。
検索上位に記事が表示されることで、結果的には沢山の人の目に触れるでしょう。
出典
適切な引用しましょう。
ひとまず、参考URLを記載すると良いと思います。
リンク集としても機能します。
参照ページが動的である場合は、パスに注意するか、説明をつけるとよいです。
例えば、ドキュメントの最新版がルートに来てしまう場合などです。
# 現時点での最新
https://doc.piccalog.net/sugoi-library/latest
# 古くなったバージョンは、サブディレクトリに格納されてしまう
https://doc.piccalog.net/sugoi-library/version/1.3.2/まとめ
当たり前ですが、
読み手が何を求めるのか?によって適切な記事の書き方は違います。
- コピペの配慮
- 環境情報の記載
は最低限意識すると良いですね。
完全に遵守しなくても、頭の片隅くらいには入れておくと良いと思います。
私自身も、良い技術記事の書き方は探求中ですので、
ぜひ、皆様の考えた最強の技術記事の書き方を構築してください!

コメント