

注意
もし試す際は、オフライン/シングルプレイのゲームのみで試しましょう。
この記事の内容を元に何らかの不都合や損害が発生したとしても、当ブログでは責任を負いません。
あくまで実験です。
活用方法案
3Dゲームのビジュアル的なデバッグ
グラフィック関係のデバッグでも、数値上は問題なくてエラーが表示されなくても
表示がバグってしまうことがあります。
そのために人力でテストしたりしますが、
Yoloの画像認識技術で正しく画面が表示されているか確認できると思います。
現実世界で使う機械学習を実験する場所としてのゲーム
近年のコンソール、PCゲームは現実と見間違えるほどグラフィックがキレイです。
そのため現実世界で使う機械学習モデルの実験場として十分機能するはずです。
結果
Arma3 (リアル系FPSゲーム)


Fallout4

Getting Over It

記事の流れ
- 1.OBSで画面をキャプチャする
- 2.仮想カメラに出力する
- 3.Python(OpenCV)に仮想カメラを入力する
- 4.Yolov5を準備する
- 5.精度と速度を検証
環境
- Windows11 22H2
- Python 3.9.13
- torch==1.12.0+cu113 (各自のcudaに合わせてください)
- venv (仮想環境)
OBSで画面をキャプチャする
OBSでゲーム画面をキャプチャします。
Pythonや機械学習とは全く関係なく、普通にゲームをOBSで取り込みます。
ウインドウキャプチャやゲームキャプチャなどで、ウインドウを指定し、取り込みます。
起動直後の画面はこんな感じ。
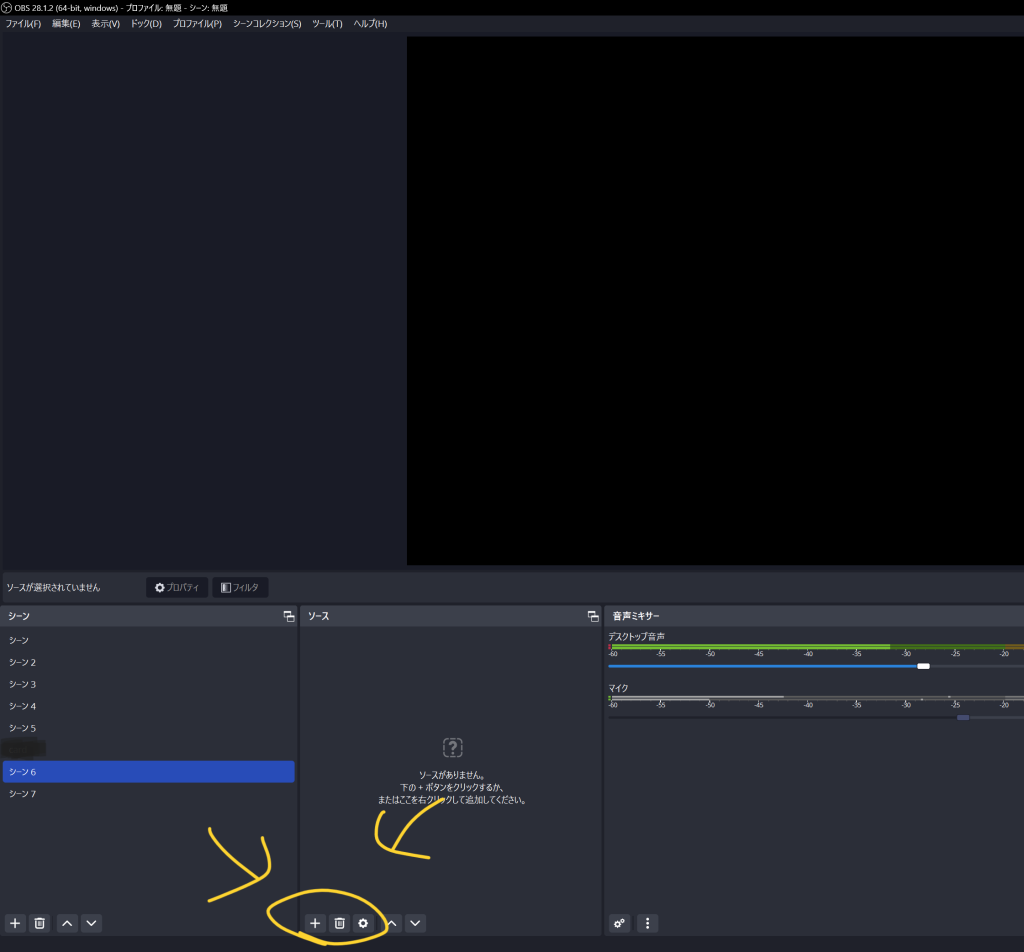
プラス+マークからウインドウキャプチャ、またはゲームキャプチャを選択します。
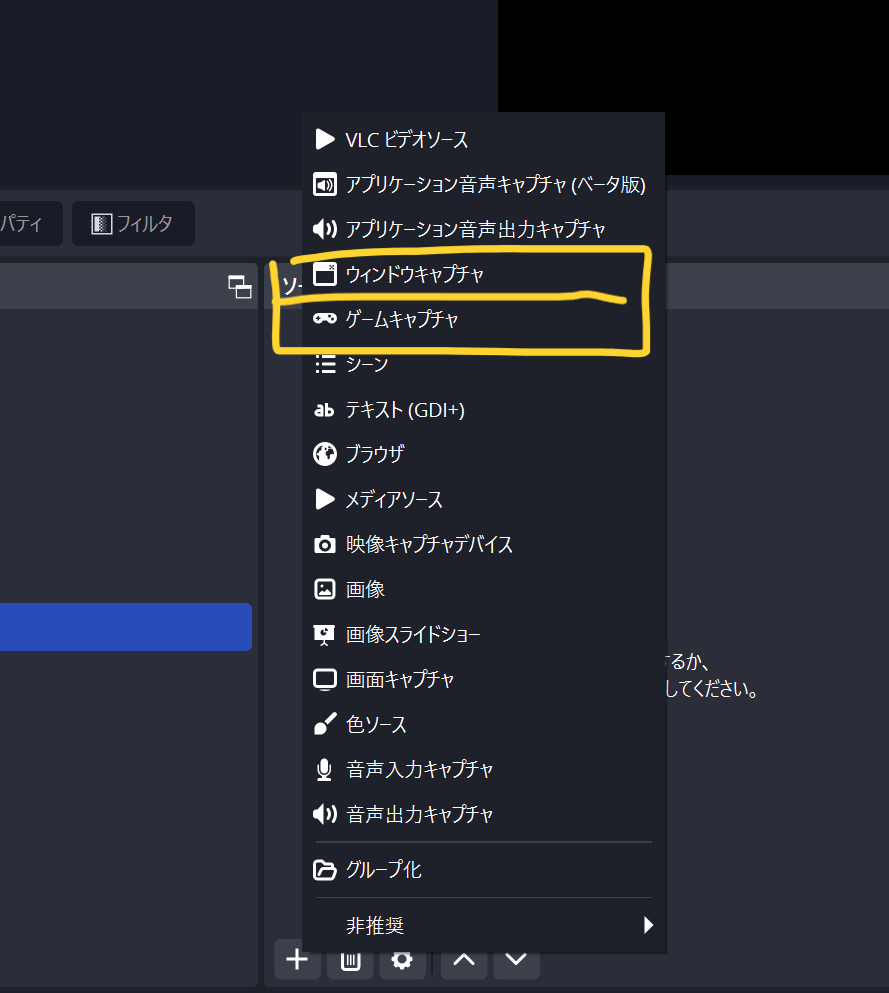
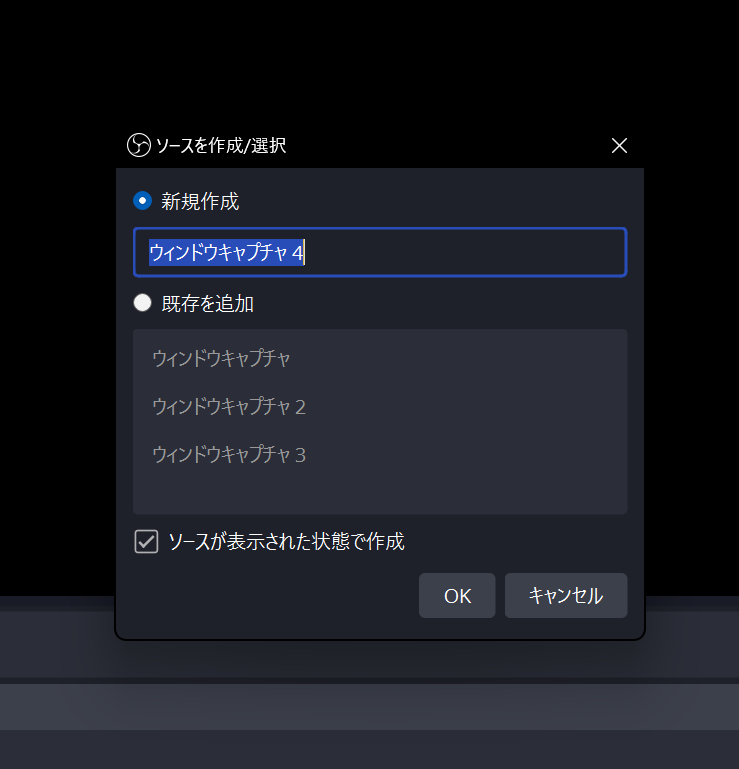
実行中のウインドウが一覧表示されます。目的のウインドウを選択。
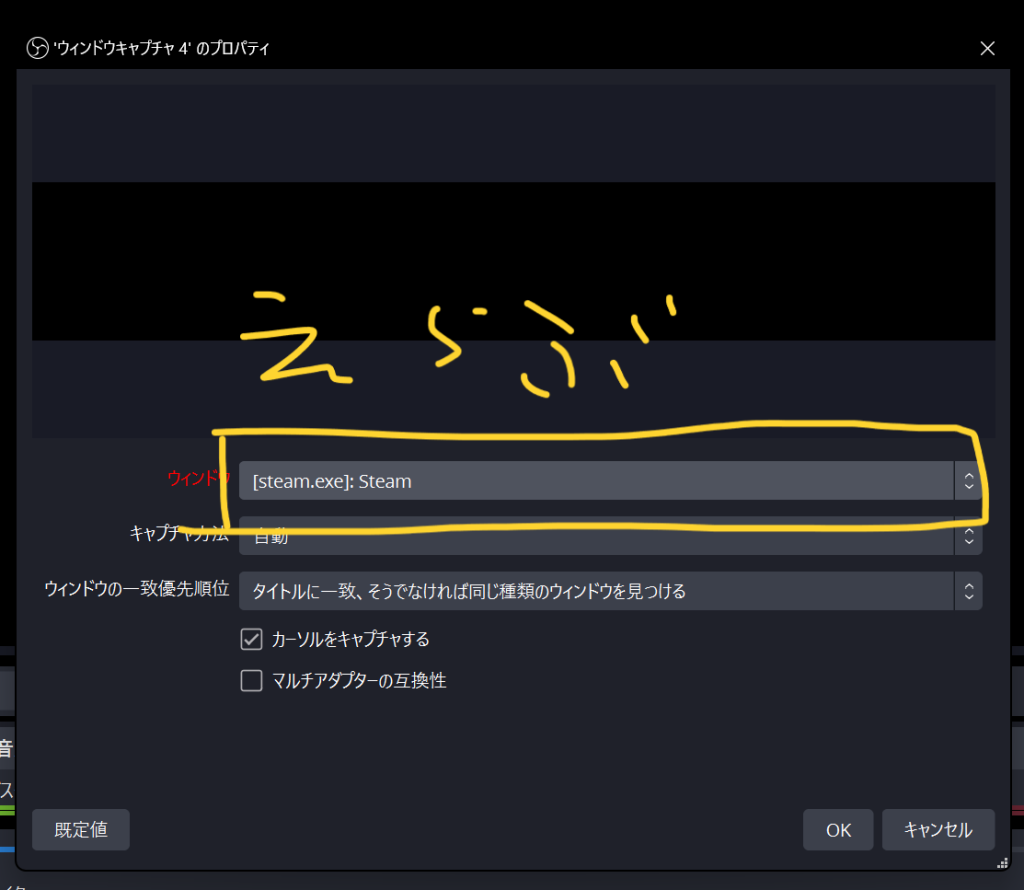
“画面キャプチャ”を使用するとデスクトップ画面も取り込むことができます。
仮想カメラに出力する
OBSで取り込んだ画面をPython(OpenCV)に渡します。
仮想カメラという手法があり、仮想的にWebカメラを作ることで、
Python(OpenCV)側では、通常のWebカメラとして扱う事ができます。

標準機能だとOpenCVで読めない問題
上記の仮想カメラの機能はOBSの標準機能でサポートされています。
が、
現状OpenCVではうまく読み取る事ができません。

VirtualCamプラグイン
詳しくは上記の参考URLを見ていただくと分かるのですが、
Githubで開発されている、別の仮想カメラプラグインを使うことで、OpenCVで読み取る事ができます。

GithubのReleaseからDLし、インストールします。
OBSを再起動し、ツール → VirtualCamが追加されており、クリック
“Start” ボタンで仮想カメラに出力されます。
(OBSの配信開始や録画開始ボタンを押す必要はありません)
Pythonにカメラを入力する
OpenCVを使って(仮想)Webカメラを読み取ります。
通常のWebカメラを読み取る方法と同じです。
ここではまず、OBSの仮想カメラが出力されているか確認します。
yoloは関係なく、OpenCVのコードです。
OpenCVを用意していない場合は以下のコマンドで導入できます。(pip環境)
$ pip install opencv-pythonimport cv2
# ストリーミングをDSHOWに変更済み
camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)
while True:
ret, frame = camera.read()
cv2.imshow('camera', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
camera.release()
cv2.destroyAllWindows()VideoCapture(0)でエラーが出る場合は、順番に数字を増やして試してください。
0→ 1→2 …
cap_msmf.cppでなんかエラー出て怒られる。
私の環境(Windows11)では、最初仮想カメラをOpenCVで読み取る事がうまくできませんでした。
具体的には以下のエラーが出力されました。
[ WARN:0] global プロジェクトパス\opencv\modules\videoio\src\cap_msmf.cpp (1113) SourceReaderCB::OnReadSample videoio(MSMF): OnReadSample() is called with error status: -1072875772その際以下の変更を加えることで解決しました。
これを
cap = cv2.VideoCapture(0)
cv2.VideoCapture()にcv2.CAP_DSHOWを追加
camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)
解決URL

Yolov5
Yoloとは?
高速で動作する、物体認識の手法です。
Githubで公開されており、学習済みモデルも提供されています。
参考元URL

基本的には上記参考URLと同じ流れです。
ですが、一部コードを追加しています
- Webカメラ(入力)の解像度を指定
- 一定精度以下の場合は表示しない。
- ウインドウが640 x 480だと小さく結果を確認しくいため、
ウインドウのサイズにまで拡大。
ソースコードは↓クリックで表示
[su_spoiler title=”ソースコードを表示する。” icon=”plus-square-1″]
import torch
import cv2
# GPUが使えるか確認、速度に影響が大きく出ます。
print(torch.cuda.is_available())
# Torch HubからYOLO V5をダウンロード
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# ローカルの学習済みデータを使う場合
# model = torch.hub.load("./yolov5",'yolov5',source='local')
camera = cv2.VideoCapture(1, cv2.CAP_DSHOW)
# 入力サイズを明示的に指定
camera.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
camera.set(cv2.CAP_PROP_FRAME_HEIGHT, 360)
while True:
ret, imgs = camera.read()
# 推論の実行
results = model(imgs, size=640)
for *box, conf, cls in results.xyxy[0]: # xyxy, confidence, class
# --- クラス名と信頼度を文字列変数に代入
s = model.names[int(cls)]+":"+'{:.1f}'.format(float(conf)*100)
# 一定精度以下のオブジェクトは除外
if float(conf)*100 > 35:
# --- 枠描画
cv2.rectangle(
imgs,
(int(box[0]), int(box[1])),
(int(box[2]), int(box[3])),
color=(255,255,0),
thickness=1,
)
# --- 文字枠と文字列描画
cv2.putText(imgs, s, (int(box[0]), int(
box[1])-5), cv2.FONT_HERSHEY_PLAIN, 1, (255,255,0), 1, cv2.LINE_AA)
# 結果を大画面で確認したいために拡大。
dst = cv2.resize(imgs, (1920, 1080))
# --- 描画した画像を表示
cv2.imshow('color', dst)
# --- 「q」キー操作があればwhileループを抜ける ---
if cv2.waitKey(1) & 0xFF == ord('q'):
break
[/su_spoiler]
精度と負荷
試したモデル
GPUで動かす都合上
ゲームとリソースを食い合ってしまって、あまりパフォーマンスが出なかった。
後でも述べるが、結局遠くの小さいオブジェクト等はどのモデルでも苦手。
| モデル名 | 体感フレームレート | 入力サイズ | 精度 | 実用 |
| yolov5s | 40 | 320 | そこそこ | 可 |
| yolov5s | 30 | 640 | それなりに良い | 可 |
| yolov5m | 20 | 320 | そこそこ | 不可 |
| yolov5x | 5 | 640 | それなりに良い | 不可 |
結局 一番軽いyolov5sが、精度と負荷のバランスが良かった。
まとめ
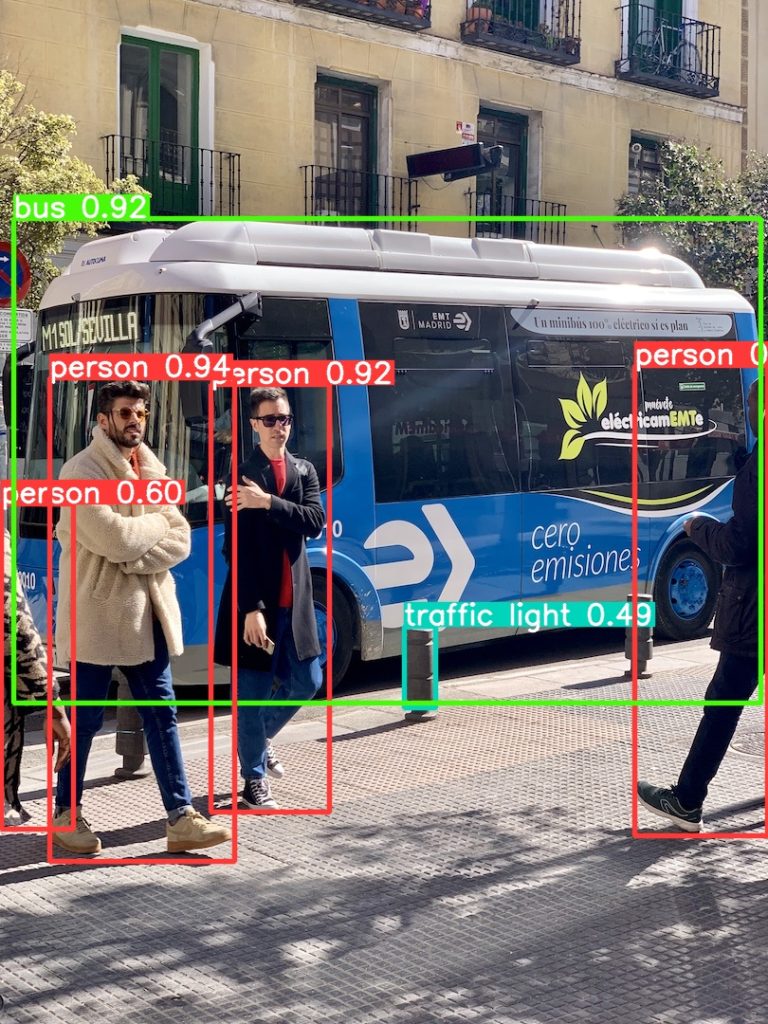
近距離で特徴的なオブジェクトは高精度で検出できる。
“人”や”車”はかなり得意です。
恐らく今回の学習済みモデルでは、学習画像がかなり多い事が要因だと思われます。
誤検知だけど領域は完璧
ラベルは誤検知だけど領域は完璧という場合がありました。
実際は武器アイテムですが、trafic lightとして認識されています。

こういった場合、自分で集めた画像で学習すればより精度を上げることが出来ると思います。
対象オブジェクトのピクセルが小さいと苦手
これも、自分で集めたデータセットで学習すれば改善すると思います。
単に角度が悪い様な感じもします。
検出不可だった画像
- 航空機(ゲーム内架空塗装)が旋回しているのを空中から見る視点
- ボートを後ろ上空から見た視点
一般的なデータセットには上記の画像が入っている感じはしませんね。
そもそもゲームでは、自分自身で視点を操作できるため、画面中央のみ切り取って
Yoloに入力してもいいかもしれません。
失敗画像はそもそも検出されませんでした。




コメント